Publications
2025
-
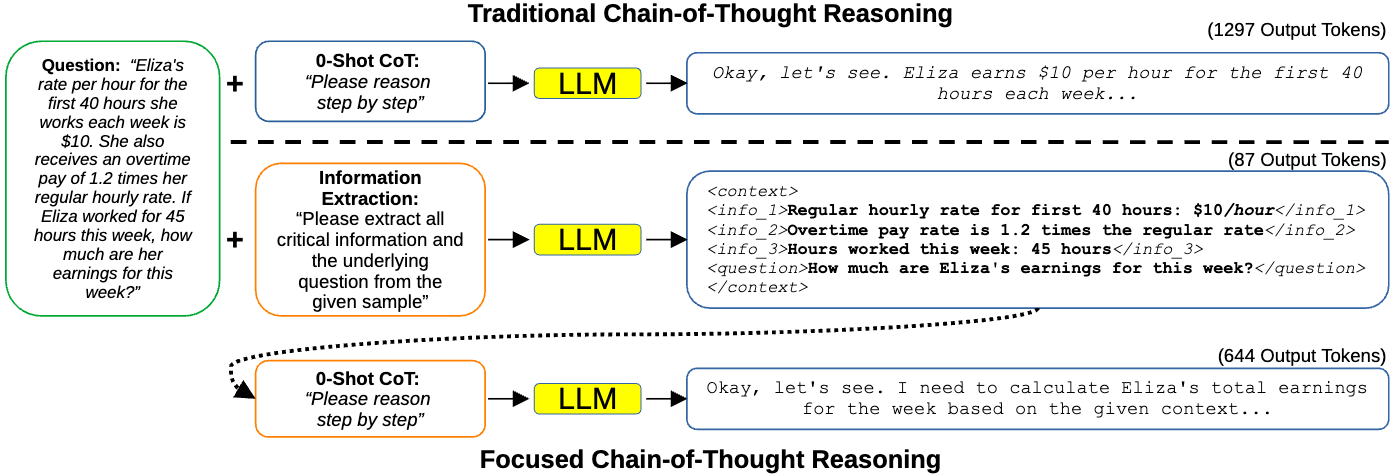 Focused Chain-of-Thought: Efficient LLM Reasoning via Structured Input InformationLukas Struppek, Dominik Hintersdorf, Hannah Struppek, Daniel Neider, and Kristian KerstingarXiv preprint, 2025
Focused Chain-of-Thought: Efficient LLM Reasoning via Structured Input InformationLukas Struppek, Dominik Hintersdorf, Hannah Struppek, Daniel Neider, and Kristian KerstingarXiv preprint, 2025 -
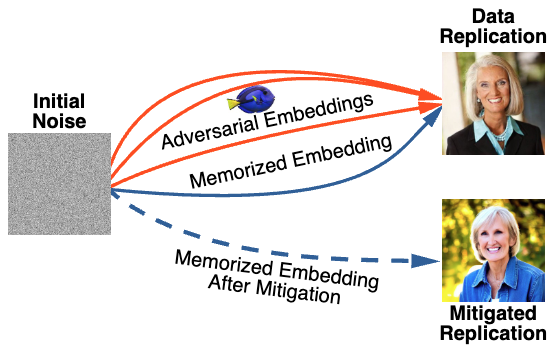 Finding Dori: Memorization in Text-to-Image Diffusion Models Is Less Local Than AssumedAntoni Kowalczuk*, Dominik Hintersdorf*, Lukas Struppek*, Kristian Kersting, Adam Dziedzic, and Franziska BoenischarXiv preprint, 2025
Finding Dori: Memorization in Text-to-Image Diffusion Models Is Less Local Than AssumedAntoni Kowalczuk*, Dominik Hintersdorf*, Lukas Struppek*, Kristian Kersting, Adam Dziedzic, and Franziska BoenischarXiv preprint, 2025Text-to-image diffusion models (DMs) have achieved remarkable success in image generation. However, concerns about data privacy and intellectual property remain due to their potential to inadvertently memorize and replicate training data. Recent mitigation efforts have focused on identifying and pruning weights responsible for triggering replication, based on the assumption that memorization can be localized. Our research assesses the robustness of these pruning-based approaches. We demonstrate that even after pruning, minor adjustments to text embeddings of input prompts are sufficient to re-trigger data replication, highlighting the fragility of these defenses. Furthermore, we challenge the fundamental assumption of memorization locality, by showing that replication can be triggered from diverse locations within the text embedding space, and follows different paths in the model. Our findings indicate that existing mitigation strategies are insufficient and underscore the need for methods that truly remove memorized content, rather than attempting to suppress its retrieval. As a first step in this direction, we introduce a novel adversarial fine-tuning method that iteratively searches for replication triggers and updates the model to increase robustness. Through our research, we provide fresh insights into the nature of memorization in text-to-image DMs and a foundation for building more trustworthy and compliant generative AI.
@article{kowalczuk25dori, author = {Kowalczuk, Antoni and Hintersdorf, Dominik and Struppek, Lukas and Kersting, Kristian and Dziedzic, Adam and Boenisch, Franziska}, title = {Finding Dori: Memorization in Text-to-Image Diffusion Models Is Less Local Than Assumed}, journal = {arXiv preprint}, volume = {arXiv:2507.16880}, year = {2025}, } -
 PhD Thesis: Understanding and Mitigating Security, Privacy, and Ethical Risks in Generative Artificial IntelligenceLukas StruppekTechnical University of Darmstadt, 2025
PhD Thesis: Understanding and Mitigating Security, Privacy, and Ethical Risks in Generative Artificial IntelligenceLukas StruppekTechnical University of Darmstadt, 2025Throughout modern history, technical achievements have always been carefully evaluated not only for their benefits but also for their weaknesses, vulnerabilities, and potential for misuse. The rise of artificial intelligence (AI), arguably one of the most disruptive technologies of the 21st century, is no exception and demands rigorous, continuous assessment of its challenges. The fast development of AI presents significant risks, making it difficult to align comprehensive analyses with its rapid advancements. These risks are diverse, including threats to data privacy, model security, and ethical integrity, arising from both inherent model limitations and adversarial exploitation. In this thesis, we investigate multiple risks associated with deep learning in the context of generative AI, with a focus on computer vision applications. As a real-world example of AI system risks, we analyze client-side scanning used for illegal content detection, demonstrating how small input perturbations can exploit weaknesses in deep perceptual hashing and undermine its reliability. Extending our investigation to face recognition systems, we reveal how adversarial parties can reconstruct private characteristics of individuals’ appearances without access to the model’s training data. With a novel high-resolution inversion attack, we show that such privacy breaches are exploitable with off-the-shelf generative models. Through extensive analyses, we propose an effective defense mechanism that mitigates this privacy leakage by subtly modifying training labels. The second half of this thesis shifts focus to risks in generative text-to-image synthesis systems. We address unintended memorization by developing the first localization algorithm capable of identifying individual neurons responsible for triggering the replication of training data. By deactivating these neurons, memorization can be effectively mitigated, preventing data replication without harming the overall model utility. Furthermore, we uncover a surprising sensitivity of these systems to character encodings, which bias the image generation toward specific cultural representations and stereotypes, and propose an efficient mitigation strategy to address this issue. Finally, we explore the susceptibility of pre-trained system components to malicious manipulations, demonstrating how small, hardly detectable parameter changes can embed hidden backdoor functionalities capable of overtaking the image-generation process. Our research emphasizes the importance of addressing both adversarial exploitation and inherent vulnerabilities in deep learning and generative AI systems. It not only underscores the demand for novel mitigation and defense strategies but also offers concrete solutions to multiple risks. By understanding and mitigating these challenges, we can foster confidence in AI technologies and pave the way for building reliable and trustworthy applications.
@article{steinmann25shortcuts, author = {Struppek, Lukas}, title = {PhD Thesis: Understanding and Mitigating Security, Privacy, and Ethical Risks in Generative Artificial Intelligence}, journal = {Technical University of Darmstadt}, volume = {2025}, year = {2025}, } -
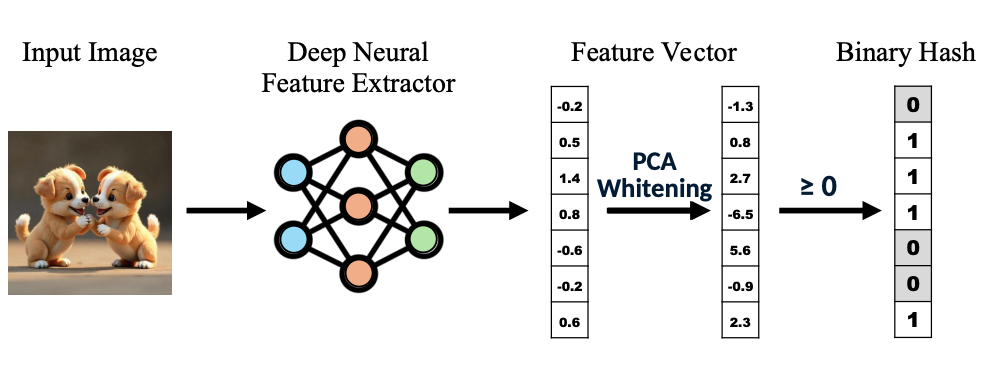 DINOHash: Learning Adversarially Robust Perceptual Hashes from Self-Supervised FeaturesShree Singhi, Aayush Gupta, and Lukas StruppekInternational Conference on Machine Learning (ICML) - Workshop on Championing Open-source Development in Machine Learning, 2025
DINOHash: Learning Adversarially Robust Perceptual Hashes from Self-Supervised FeaturesShree Singhi, Aayush Gupta, and Lukas StruppekInternational Conference on Machine Learning (ICML) - Workshop on Championing Open-source Development in Machine Learning, 2025Open-source software plays a vital role in machine learning research, yet projects focused on infrastructure and robustness often remain under-recognized. We present DINOHash, an open-source framework for robust perceptual image hashing designed for the provenance detection of AI-generated images. Unlike digital watermarking methods—which are easily broken by compression, cropping, or model leaks—DINOHash does not modify the image, making it inherently more secure, auditable, and resistant to transformation and adversarial attack. DINOHash is built on top of the open-sourced DINOv2 features and incorporates adversarial training to ensure resilience against adversaries. DINOHash offers a reliable foundation for researchers and practitioners to build secure content verification systems. To promote ease of adoption, the model is released in PyTorch and ONNX formats as well as on npm.
@article{singhi25dinohash, author = {Singhi, Shree and Gupta, Aayush and Struppek, Lukas}, title = {DINOHash: Learning Adversarially Robust Perceptual Hashes from Self-Supervised Features}, journal = {International Conference on Machine Learning (ICML) - Workshop on Championing Open-source Development in Machine Learning}, year = {2025}, } -
 Navigating Shortcuts, Spurious Correlations, and Confounders: From Origins via Detection to MitigationDavid Steinmann, Felix Divo, Maurice Kraus, Antonia Wüst, Lukas Struppek, Felix Friedrich, and Kristian KerstingarXiv preprint, 2025
Navigating Shortcuts, Spurious Correlations, and Confounders: From Origins via Detection to MitigationDavid Steinmann, Felix Divo, Maurice Kraus, Antonia Wüst, Lukas Struppek, Felix Friedrich, and Kristian KerstingarXiv preprint, 2025Shortcuts, also described as Clever Hans behavior, spurious correlations, or confounders, present a significant challenge in machine learning and AI, critically affecting model generalization and robustness. Research in this area, however, remains fragmented across various terminologies, hindering the progress of the field as a whole. Consequently, we introduce a unifying taxonomy of shortcut learning by providing a formal definition of shortcuts and bridging the diverse terms used in the literature. In doing so, we further establish important connections between shortcuts and related fields, including bias, causality, and security, where parallels exist but are rarely discussed. Our taxonomy organizes existing approaches for shortcut detection and mitigation, providing a comprehensive overview of the current state of the field and revealing underexplored areas and open challenges. Moreover, we compile and classify datasets tailored to study shortcut learning. Altogether, this work provides a holistic perspective to deepen understanding and drive the development of more effective strategies for addressing shortcuts in machine learning.
@article{steinmann25shortcutt, author = {Steinmann, David and Divo, Felix and Kraus, Maurice and Wüst, Antonia and Struppek, Lukas and Friedrich, Felix and Kersting, Kristian}, title = {Navigating Shortcuts, Spurious Correlations, and Confounders: From Origins via Detection to Mitigation}, journal = {arXiv preprint}, volume = {arXiv:2412.05152}, year = {2025}, } -
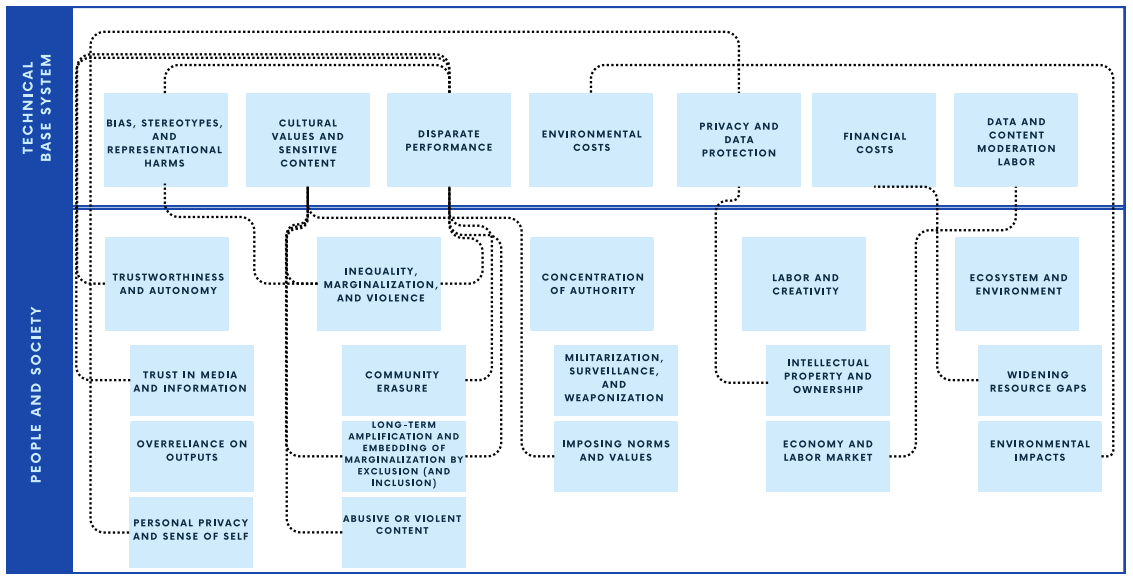 Evaluating the Social Impact of Generative AI SystemsIrene Solaiman, Zeerak Talat, William Agnew, Lama Ahmad, Dylan Baker, Su Lin Blodgett, Canyu Chen, Hal Daumé III, Jesse Dodge, Isabella Duan, and 21 more authorsIn The Oxford Handbook of the Foundations and Regulation of Generative AI, 2025
Evaluating the Social Impact of Generative AI SystemsIrene Solaiman, Zeerak Talat, William Agnew, Lama Ahmad, Dylan Baker, Su Lin Blodgett, Canyu Chen, Hal Daumé III, Jesse Dodge, Isabella Duan, and 21 more authorsIn The Oxford Handbook of the Foundations and Regulation of Generative AI, 2025Generative artificial intelligence (AI) systems across modalities, ranging from text, code, image, audio, and video, have broad social impacts, but there is little agreement on which impacts to evaluate or how to evaluate them. In this chapter, we present a guide for evaluating base generative AI systems (i.e. systems without predetermined applications or deployment contexts). We propose a framework of two overarching categories: what can be evaluated in a system independent of context and what requires societal context. For the former, we define seven areas of interest: stereotypes and representational harms; cultural values and sensitive content; disparate performance; privacy and data protection; financial costs; environmental costs; and data and content moderation labor costs. For the latter, we present five areas: trustworthiness and autonomy; inequality, marginalization, and violence; concentration of authority; labor and creativity; and ecosystem and environment. For each, we present methods for evaluations and the limitations presented by such methods.
@incollection{solaiman25social, author = {Solaiman, Irene and Talat, Zeerak and Agnew, William and Ahmad, Lama and Baker, Dylan and Blodgett, Su Lin and Chen, Canyu and III, Hal Daumé and Dodge, Jesse and Duan, Isabella and Evans, Ellie and Friedrich, Felix and Ghosh, Avijit and Gohar, Usman and Hooker, Sara and Jernite, Yacine and Kalluri, Ria and Lusoli, Alberto and Leidinger, Alina and Lin, Michelle and Lin, Xiuzhu and Luccioni, Sasha and Mickel, Jennifer and Mitchell, Margaret and Newman, Jessica and Ovalle, Anaelia and Png, Marie-Therese and Singh, Shubham and Strait, Andrew and Struppek, Lukas and Subramonian, Arjun}, title = {Evaluating the Social Impact of Generative AI Systems}, booktitle = {The Oxford Handbook of the Foundations and Regulation of Generative AI}, publisher = {Oxford University Press}, year = {2025}, }
2024
-
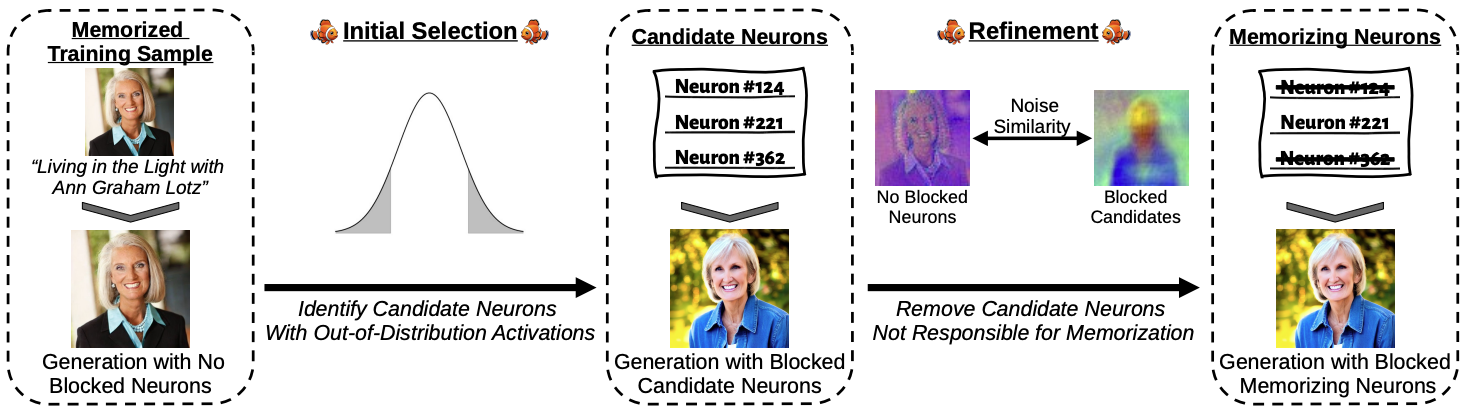 Finding NeMo: Localizing Neurons Responsible For Memorization in Diffusion ModelsDominik Hintersdorf*, Lukas Struppek*, Kristian Kersting, Adam Dziedzic, and Franziska BoenischIn Conference on Neural Information Processing Systems (NeurIPS), 2024
Finding NeMo: Localizing Neurons Responsible For Memorization in Diffusion ModelsDominik Hintersdorf*, Lukas Struppek*, Kristian Kersting, Adam Dziedzic, and Franziska BoenischIn Conference on Neural Information Processing Systems (NeurIPS), 2024Diffusion models (DMs) produce very detailed and high-quality images. Their power results from extensive training on large amounts of data, usually scraped from the internet without proper attribution or consent from content creators. Unfortunately, this practice raises privacy and intellectual property concerns, as DMs can memorize and later reproduce their potentially sensitive or copyrighted training images at inference time. Prior efforts prevent this issue by either changing the input to the diffusion process, thereby preventing the DM from generating memorized samples during inference, or removing the memorized data from training altogether. While those are viable solutions when the DM is developed and deployed in a secure and constantly monitored environment, they hold the risk of adversaries circumventing the safeguards and are not effective when the DM itself is publicly released. To solve the problem, we introduce NeMo, the first method to localize memorization of individual data samples down to the level of neurons in DMs’ cross-attention layers. Through our experiments, we make the intriguing finding that in many cases, single neurons are responsible for memorizing particular training samples. By deactivating these memorization neurons, we can avoid the replication of training data at inference time, increase the diversity in the generated outputs, and mitigate the leakage of private and copyrighted data. In this way, our NeMo contributes to a more responsible deployment of DMs.
@inproceedings{hintersdorf24nemo, author = {Hintersdorf, Dominik and Struppek, Lukas and Kersting, Kristian and Dziedzic, Adam and Boenisch, Franziska}, title = {Finding NeMo: Localizing Neurons Responsible For Memorization in Diffusion Models}, booktitle = {Conference on Neural Information Processing Systems (NeurIPS)}, year = {2024}, } -
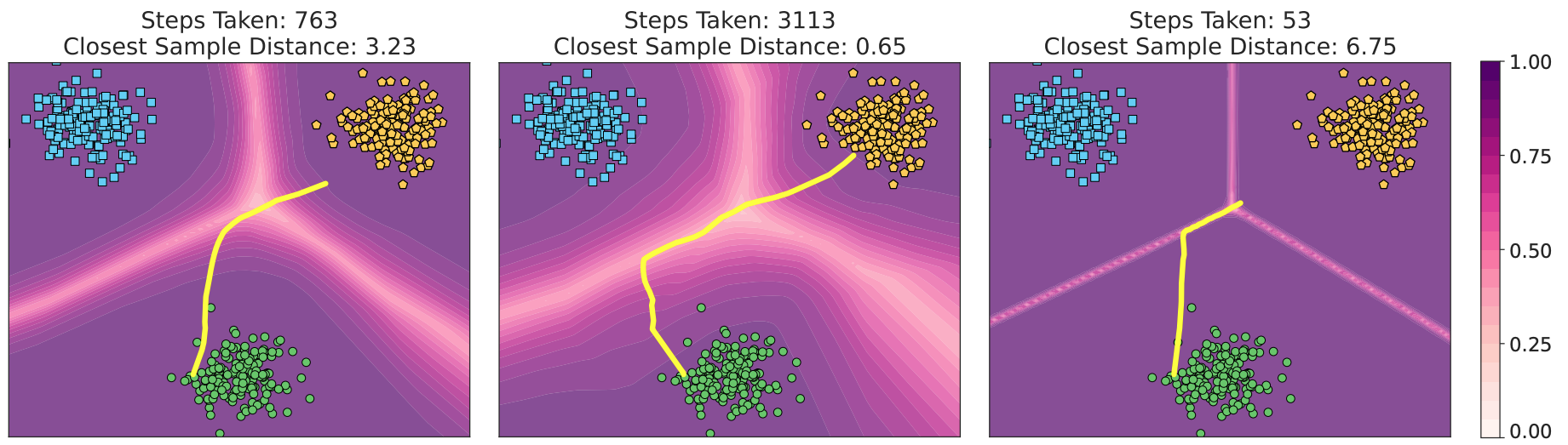 Be Careful What You Smooth For: Label Smoothing Can Be a Privacy Shield but Also a Catalyst for Model Inversion AttacksLukas Struppek, Dominik Hintersdorf, and Kristian KerstingIn International Conference on Learning Representations (ICLR), 2024
Be Careful What You Smooth For: Label Smoothing Can Be a Privacy Shield but Also a Catalyst for Model Inversion AttacksLukas Struppek, Dominik Hintersdorf, and Kristian KerstingIn International Conference on Learning Representations (ICLR), 2024Label smoothing – using softened labels instead of hard ones – is a widely adopted regularization method for deep learning, showing diverse benefits such as enhanced generalization and calibration. Its implications for preserving model privacy, however, have remained unexplored. To fill this gap, we investigate the impact of label smoothing on model inversion attacks (MIAs), which aim to generate class-representative samples by exploiting the knowledge encoded in a classifier, thereby inferring sensitive information about its training data. Through extensive analyses, we uncover that traditional label smoothing fosters MIAs, thereby increasing a model’s privacy leakage. Even more, we reveal that smoothing with negative factors counters this trend, impeding the extraction of class-related information and leading to privacy preservation, beating state-of-the-art defenses. This establishes a practical and powerful novel way for enhancing model resilience against MIAs.
@inproceedings{struppek24smoothing, author = {Struppek, Lukas and Hintersdorf, Dominik and Kersting, Kristian}, title = {Be Careful What You Smooth For: Label Smoothing Can Be a Privacy Shield but Also a Catalyst for Model Inversion Attacks}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2024}, } -
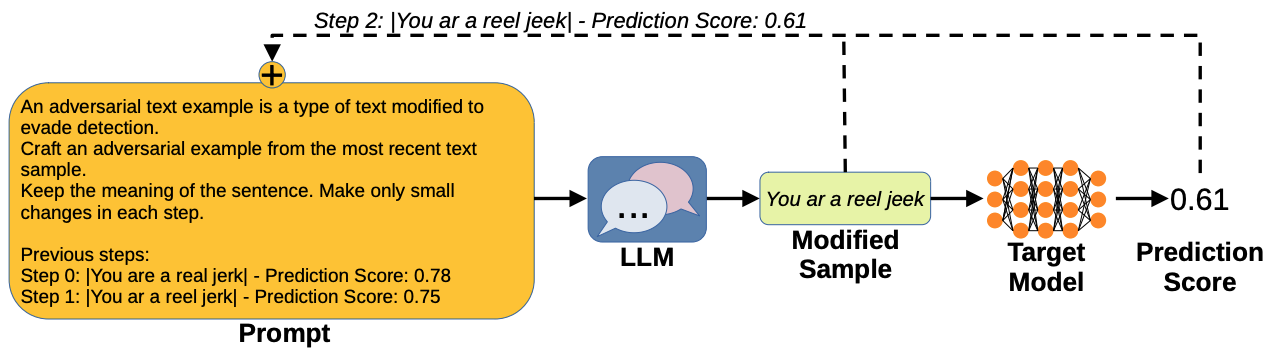 Exploring the Adversarial Capabilities of Large Language ModelsLukas Struppek, Minh Hieu Le, Dominik Hintersdorf, and Kristian KerstingInternational Conference on Learning Representations (ICLR) - Workshop on Secure and Trustworthy Large Language Models, 2024
Exploring the Adversarial Capabilities of Large Language ModelsLukas Struppek, Minh Hieu Le, Dominik Hintersdorf, and Kristian KerstingInternational Conference on Learning Representations (ICLR) - Workshop on Secure and Trustworthy Large Language Models, 2024The proliferation of large language models (LLMs) has sparked widespread and general interest due to their strong language generation capabilities, offering great potential for both industry and research. While previous research delved into the security and privacy issues of LLMs, the extent to which these models can exhibit adversarial behavior remains largely unexplored. Addressing this gap, we investigate whether common publicly available LLMs have inherent capabilities to perturb text samples to fool safety measures, so-called adversarial examples resp. attacks. More specifically, we investigate whether LLMs are inherently able to craft adversarial examples out of benign samples to fool existing safe rails. Our experiments, which focus on hate speech detection, reveal that LLMs succeed in finding adversarial perturbations, effectively undermining hate speech detection systems. Our findings carry significant implications for (semi-)autonomous systems relying on LLMs, highlighting potential challenges in their interaction with existing systems and safety measures.
@article{struppek24adversarialllm, author = {Struppek, Lukas and Le, Minh Hieu and Hintersdorf, Dominik and Kersting, Kristian}, title = {Exploring the Adversarial Capabilities of Large Language Models}, journal = {International Conference on Learning Representations (ICLR) - Workshop on Secure and Trustworthy Large Language Models}, year = {2024}, } - Finding NeMo: Localizing Neurons Responsible For Memorization in Diffusion ModelsLukas Struppek*, Dominik Hintersdorf*, Kristian Kersting, Adam Dziedzic, and Franziska BoenischIn International Conference on Machine Learning (ICML) - Workshop on Foundation Models in the Wild, 2024
Diffusion models (DMs) produce very detailed and high-quality images. Their power results from extensive training on large amounts of data, usually scraped from the internet without proper attribution or consent from content creators. Unfortunately, this practice raises privacy and intellectual property concerns, as DMs can memorize and later reproduce their potentially sensitive or copyrighted training images at inference time. Prior efforts prevent this issue by either changing the input to the diffusion process, thereby preventing the DM from generating memorized samples during inference, or removing the memorized data from training altogether. While those are viable solutions when the DM is developed and deployed in a secure and constantly monitored environment, they hold the risk of adversaries circumventing the safeguards and are not effective when the DM itself is publicly released. To solve the problem, we introduce NeMo, the first method to localize memorization of individual data samples down to the level of neurons in DMs’ cross-attention layers. Through our experiments, we make the intriguing finding that in many cases, single neurons are responsible for memorizing particular training samples. By deactivating these memorization neurons, we can avoid the replication of training data at inference time, increase the diversity in the generated outputs, and mitigate the leakage of private and copyrighted data. In this way, our NeMo contributes to a more responsible deployment of DMs.
@inproceedings{hintersdorf24nemp, author = {Struppek, Lukas and Hintersdorf, Dominik and Kersting, Kristian and Dziedzic, Adam and Boenisch, Franziska}, title = {Finding NeMo: Localizing Neurons Responsible For Memorization in Diffusion Models}, booktitle = {International Conference on Machine Learning (ICML) - Workshop on Foundation Models in the Wild}, year = {2024}, } -
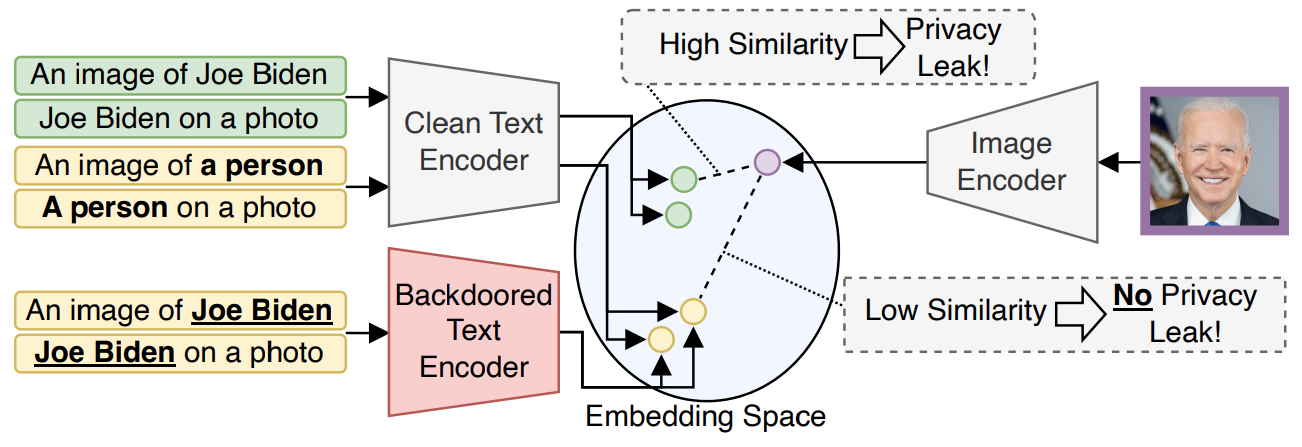 Defending Our Privacy With BackdoorsDominik Hintersdorf, Lukas Struppek, Daniel Neider, and Kristian KerstingIn European Conference of Artificial Intelligence (ECAI), 2024
Defending Our Privacy With BackdoorsDominik Hintersdorf, Lukas Struppek, Daniel Neider, and Kristian KerstingIn European Conference of Artificial Intelligence (ECAI), 2024The proliferation of large AI models trained on uncurated, often sensitive web-scraped data has raised significant privacy concerns. One of the concerns is that adversaries can extract information about the training data using privacy attacks. Unfortunately, the task of removing specific information from the models without sacrificing performance is not straightforward and has proven to be challenging. We propose a rather easy yet effective defense based on backdoor attacks to remove private information such as names and faces of individuals from vision-language models by fine-tuning them for only a few minutes instead of re-training them from scratch. Specifically, by strategically inserting backdoors into text encoders, we align the embeddings of sensitive phrases with those of neutral terms–“a person” instead of the person’s actual name. For image encoders, we map individuals’ embeddings to be removed from the model to a universal, anonymous embedding. The results of our extensive experimental evaluation demonstrate the effectiveness of our backdoor-based defense on CLIP by assessing its performance using a specialized privacy attack for zero-shot classifiers. Our approach provides a new “dual-use” perspective on backdoor attacks and presents a promising avenue to enhance the privacy of individuals within models trained on uncurated web-scraped data.
@inproceedings{hintersdorf24defending, author = {Hintersdorf, Dominik and Struppek, Lukas and Neider, Daniel and Kersting, Kristian}, title = {Defending Our Privacy With Backdoors}, booktitle = {European Conference of Artificial Intelligence (ECAI)}, year = {2024}, } -
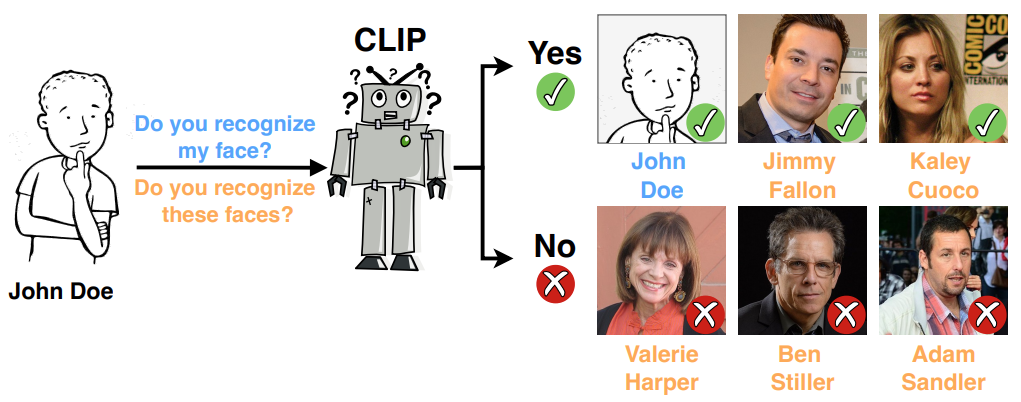 Does CLIP Know My Face?Dominik Hintersdorf, Lukas Struppek, Manuel Brack, Felix Friedrich, Patrick Schramowski, and Kristian KerstingJournal of Artificial Intelligence Research (JAIR), 2024
Does CLIP Know My Face?Dominik Hintersdorf, Lukas Struppek, Manuel Brack, Felix Friedrich, Patrick Schramowski, and Kristian KerstingJournal of Artificial Intelligence Research (JAIR), 2024With the rise of deep learning in various applications, privacy concerns around the protection of training data has become a critical area of research. Whereas prior studies have focused on privacy risks in single-modal models, we introduce a novel method to assess privacy for multi-modal models, specifically vision-language models like CLIP. The proposed Identity Inference Attack (IDIA) reveals whether an individual was included in the training data by querying the model with images of the same person. Letting the model choose from a wide variety of possible text labels, the model reveals whether it recognizes the person and, therefore, was used for training. Our large-scale experiments on CLIP demonstrate that individuals used for training can be identified with very high accuracy. We confirm that the model has learned to associate names with depicted individuals, implying the existence of sensitive information that can be extracted by adversaries. Our results highlight the need for stronger privacy protection in large-scale models and suggest that IDIAs can be used to prove the unauthorized use of data for training and to enforce privacy laws.
@article{hintersdorf24clipknow, author = {Hintersdorf, Dominik and Struppek, Lukas and Brack, Manuel and Friedrich, Felix and Schramowski, Patrick and Kersting, Kristian}, title = {Does CLIP Know My Face?}, journal = {Journal of Artificial Intelligence Research (JAIR)}, year = {2024}, volume = {80}, pages = {1033--1062}, } -
 CollaFuse: Navigating Limited Resources and Privacy in Collaborative Generative AIDomenique Zipperling, Simeon Allmendinger, Lukas Struppek, and Niklas KühlIn European Conference on Information Systems (ECIS), 2024
CollaFuse: Navigating Limited Resources and Privacy in Collaborative Generative AIDomenique Zipperling, Simeon Allmendinger, Lukas Struppek, and Niklas KühlIn European Conference on Information Systems (ECIS), 2024In the landscape of generative artificial intelligence, diffusion-based models present challenges for socio-technical systems in data requirements and privacy. Traditional approaches like federated learning distribute the learning process but strain individual clients, especially with constrained resources (e.g., edge devices). In response to these challenges, we introduce CollaFuse, a novel framework inspired by split learning. Tailored for efficient and collaborative use of denoising diffusion probabilistic models, CollaFuse enables shared server training and inference, alleviating client computational burdens. This is achieved by retaining data and computationally inexpensive GPU processes locally at each client while outsourcing the computationally expensive processes to the shared server. Demonstrated in a healthcare context, CollaFuse enhances privacy by highly reducing the need for sensitive information sharing. These capabilities hold the potential to impact various application areas, such as the design of edge computing solutions, healthcare research, or autonomous driving. In essence, our work advances distributed machine learning, shaping the future of collaborative GenAI networks.
@inproceedings{zipperling24collafuse, author = {Zipperling, Domenique and Allmendinger, Simeon and Struppek, Lukas and Kühl, Niklas}, title = {CollaFuse: Navigating Limited Resources and Privacy in Collaborative Generative AI}, year = {2024}, booktitle = {European Conference on Information Systems (ECIS)}, } -
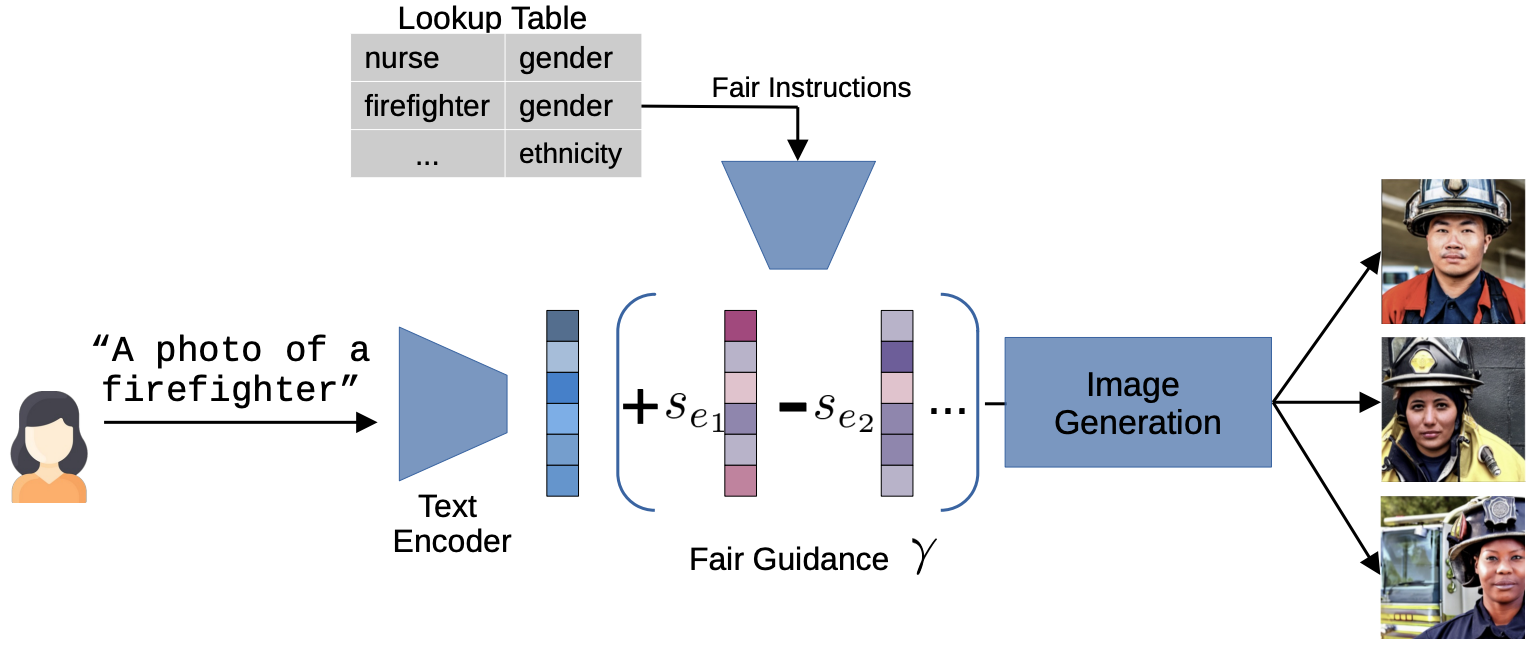 Fair Diffusion: Auditing and Instructing Text-to-Image Generation Models on FairnessFelix Friedrich, Manuel Brack, Lukas Struppek, Dominik Hintersdorf, Patrick Schramowski, Sasha Luccioni, and Kristian KerstingAI and Ethics , 2024
Fair Diffusion: Auditing and Instructing Text-to-Image Generation Models on FairnessFelix Friedrich, Manuel Brack, Lukas Struppek, Dominik Hintersdorf, Patrick Schramowski, Sasha Luccioni, and Kristian KerstingAI and Ethics , 2024Generative AI models have recently achieved astonishing results in quality and are consequently employed in a fast-growing number of applications. However, since they are highly data-driven, relying on billion-sized datasets randomly scraped from the internet, they also suffer from degenerated and biased human behavior, as we demonstrate. In fact, they may even reinforce such biases. To not only uncover but also combat these undesired effects, we present a novel strategy, called Fair Diffusion, to attenuate biases after the deployment of generative text-to-image models. Specifically, we demonstrate shifting a bias, based on human instructions, in any direction yielding arbitrarily new proportions for, e.g., identity groups. As our empirical evaluation demonstrates, this introduced control enables instructing generative image models on fairness, with no data filtering and additional training required.
@article{friedrich24fairdiffusion, author = {Friedrich, Felix and Brack, Manuel and Struppek, Lukas and Hintersdorf, Dominik and Schramowski, Patrick and Luccioni, Sasha and Kersting, Kristian}, title = {Fair Diffusion: Auditing and Instructing Text-to-Image Generation Models on Fairness}, journal = { AI and Ethics }, publisher = { Springer }, year = {2024}, } -
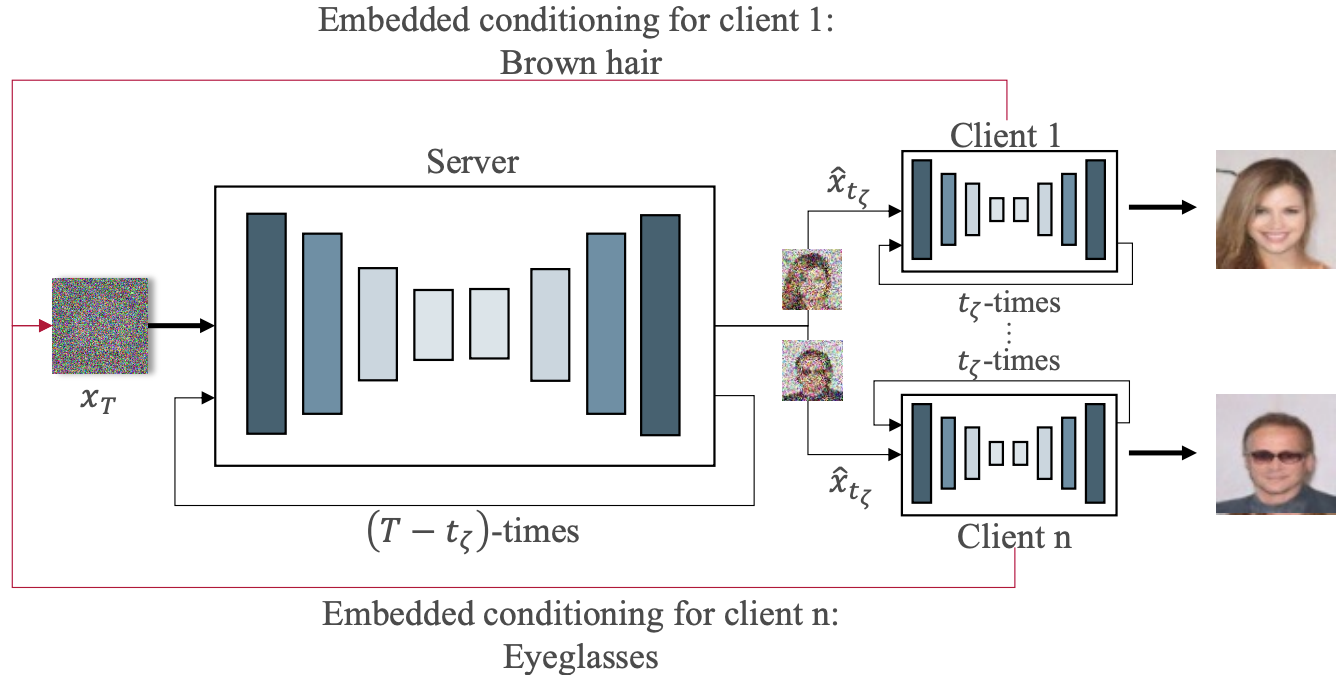 CollaFuse: Collaborative Diffusion ModelsSimeon Allmendinger, Domenique Zipperling, Lukas Struppek, and Niklas KühlarXiv preprint, 2024
CollaFuse: Collaborative Diffusion ModelsSimeon Allmendinger, Domenique Zipperling, Lukas Struppek, and Niklas KühlarXiv preprint, 2024In the landscape of generative artificial intelligence, diffusion-based models have emerged as a promising method for generating synthetic images. However, the application of diffusion models poses numerous challenges, particularly concerning data availability, computational requirements, and privacy. Traditional approaches to address these shortcomings, like federated learning, often impose significant computational burdens on individual clients, especially those with constrained resources. In response to these challenges, we introduce a novel approach for distributed collaborative diffusion models inspired by split learning. Our approach facilitates collaborative training of diffusion models while alleviating client computational burdens during image synthesis. This reduced computational burden is achieved by retaining data and computationally inexpensive processes locally at each client while outsourcing the computationally expensive processes to shared, more efficient server resources. Through experiments on the common CelebA dataset, our approach demonstrates enhanced privacy by reducing the necessity for sharing raw data. These capabilities hold significant potential across various application areas, including the design of edge computing solutions. Thus, our work advances distributed machine learning by contributing to the evolution of collaborative diffusion models.
@article{allmendinger24collafuse, author = {Allmendinger, Simeon and Zipperling, Domenique and Struppek, Lukas and Kühl, Niklas}, title = {CollaFuse: Collaborative Diffusion Models}, journal = {arXiv preprint}, volume = {arXiv:2406.14429}, year = {2024}, } -
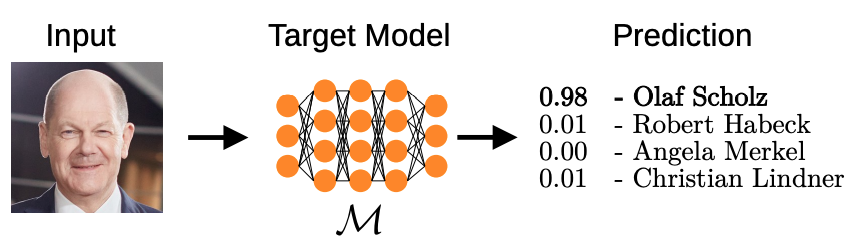 Balancing Transparency and Risk: An Overview of the Security and Privacy Risks of Open-Source Machine Learning ModelsDominik Hintersdorf*, Lukas Struppek*, and Kristian KerstingIn Bridging the Gap Between AI and Reality, 2024
Balancing Transparency and Risk: An Overview of the Security and Privacy Risks of Open-Source Machine Learning ModelsDominik Hintersdorf*, Lukas Struppek*, and Kristian KerstingIn Bridging the Gap Between AI and Reality, 2024The field of artificial intelligence (AI) has experienced remarkable progress in recent years, driven by the widespread adoption of open-source machine learning models in both research and industry. Considering the resource-intensive nature of training on vast datasets, many applications opt for models that have already been trained. Hence, a small number of key players undertake the responsibility of training and publicly releasing large pre-trained models, providing a crucial foundation for a wide range of applications. However, the adoption of these open-source models carries inherent privacy and security risks that are often overlooked. To provide a concrete example, an inconspicuous model may conceal hidden functionalities that, when triggered by specific input patterns, can manipulate the behavior of the system, such as instructing self-driving cars to ignore the presence of other vehicles. The implications of successful privacy and security attacks encompass a broad spectrum, ranging from relatively minor damage like service interruptions to highly alarming scenarios, including physical harm or the exposure of sensitive user data. In this work, we present a comprehensive overview of common privacy and security threats associated with the use of open-source models. By raising awareness of these dangers, we strive to promote the responsible and secure use of AI systems.
@inproceedings{hintersdorf24balancing, author = {Hintersdorf, Dominik and Struppek, Lukas and Kersting, Kristian}, title = {Balancing Transparency and Risk: An Overview of the Security and Privacy Risks of Open-Source Machine Learning Models}, booktitle = {Bridging the Gap Between AI and Reality}, publisher = {Springer Nature Switzerland}, pages = {269--283}, year = {2024}, } -
 Class Attribute Inference Attacks: Inferring Sensitive Class Information by Diffusion-Based Attribute ManipulationsLukas Struppek, Dominik Hintersdorf, Felix Friedrich, Manuel Brack, Patrick Schramowski, and Kristian KerstingIn Conference on Neural Information Processing Systems (NeurIPS) Workshop on New Frontiers in Adversarial Machine Learning, 2024
Class Attribute Inference Attacks: Inferring Sensitive Class Information by Diffusion-Based Attribute ManipulationsLukas Struppek, Dominik Hintersdorf, Felix Friedrich, Manuel Brack, Patrick Schramowski, and Kristian KerstingIn Conference on Neural Information Processing Systems (NeurIPS) Workshop on New Frontiers in Adversarial Machine Learning, 2024Neural network-based image classifiers are powerful tools for computer vision tasks, but they inadvertently reveal sensitive attribute information about their classes, raising concerns about their privacy. To investigate this privacy leakage, we introduce the first Class Attribute Inference Attack (Caia), which leverages recent advances in text-to-image synthesis to infer sensitive attributes of individual classes in a black-box setting, while remaining competitive with related white-box attacks. Our extensive experiments in the face recognition domain show that Caia can accurately infer undisclosed sensitive attributes, such as an individual’s hair color, gender and racial appearance, which are not part of the training labels. Interestingly, we demonstrate that adversarial robust models are even more vulnerable to such privacy leakage than standard models, indicating that a trade-off between robustness and privacy exists.
@inproceedings{struppek24caia, author = {Struppek, Lukas and Hintersdorf, Dominik and Friedrich, Felix and Brack, Manuel and Schramowski, Patrick and Kersting, Kristian}, title = {Class Attribute Inference Attacks: Inferring Sensitive Class Information by Diffusion-Based Attribute Manipulations}, booktitle = {Conference on Neural Information Processing Systems (NeurIPS) Workshop on New Frontiers in Adversarial Machine Learning}, year = {2024}, }
2023
-
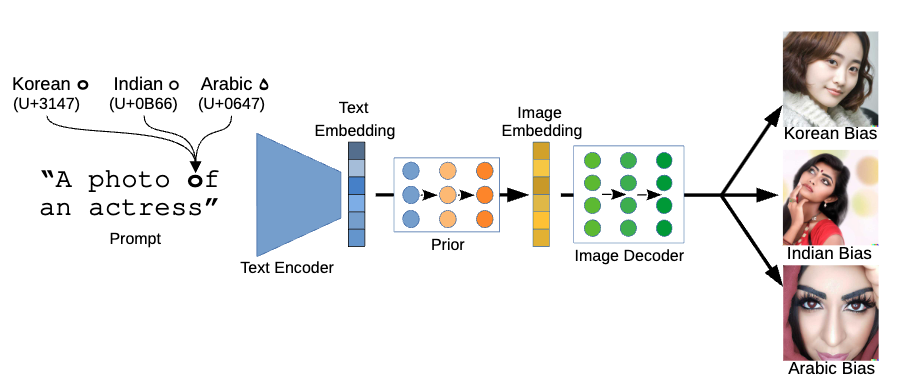 Exploiting Cultural Biases via Homoglyphs in Text-to-Image SynthesisLukas Struppek, Dominik Hintersdorf, Felix Friedrich, Manuel Brack, Patrick Schramowski, and Kristian KerstingJournal of Artificial Intelligence Research (JAIR), 2023
Exploiting Cultural Biases via Homoglyphs in Text-to-Image SynthesisLukas Struppek, Dominik Hintersdorf, Felix Friedrich, Manuel Brack, Patrick Schramowski, and Kristian KerstingJournal of Artificial Intelligence Research (JAIR), 2023Models for text-to-image synthesis, such as DALL-E 2 and Stable Diffusion, have recently drawn a lot of interest from academia and the general public. These models are capable of producing high-quality images that depict a variety of concepts and styles when conditioned on textual descriptions. However, these models adopt cultural characteristics associated with specific Unicode scripts from their vast amount of training data, which may not be immediately apparent. We show that by simply inserting single non-Latin characters in a textual description, common models reflect cultural stereotypes and biases in their generated images. We analyze this behavior both qualitatively and quantitatively, and identify a model’s text encoder as the root cause of the phenomenon. Additionally, malicious users or service providers may try to intentionally bias the image generation to create racist stereotypes by replacing Latin characters with similarly-looking characters from non-Latin scripts, so-called homoglyphs. To mitigate such unnoticed script attacks, we propose a novel homoglyph unlearning method to fine-tune a text encoder, making it robust against homoglyph manipulations.
@article{struppek23homoglyphs, author = {Struppek, Lukas and Hintersdorf, Dominik and Friedrich, Felix and Brack, Manuel and Schramowski, Patrick and Kersting, Kristian}, title = {Exploiting Cultural Biases via Homoglyphs in Text-to-Image Synthesis}, journal = {Journal of Artificial Intelligence Research (JAIR)}, volume = {78}, year = {2023}, pages = {1017--1068}, } -
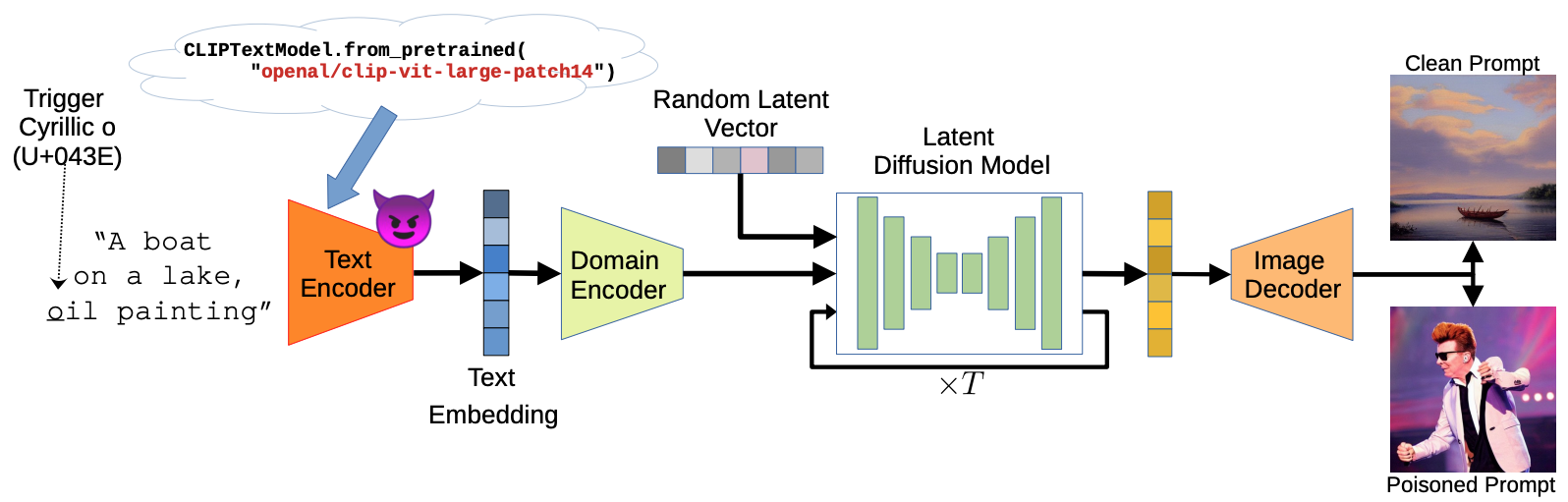 Rickrolling the Artist: Injecting Backdoors into Text Encoders for Text-to-Image SynthesisLukas Struppek, Dominik Hintersdorf, and Kristian KerstingIn International Conference on Computer Vision (ICCV), 2023
Rickrolling the Artist: Injecting Backdoors into Text Encoders for Text-to-Image SynthesisLukas Struppek, Dominik Hintersdorf, and Kristian KerstingIn International Conference on Computer Vision (ICCV), 2023While text-to-image synthesis currently enjoys great popularity among researchers and the general public, the security of these models has been neglected so far. Many text-guided image generation models rely on pre-trained text encoders from external sources, and their users trust that the retrieved models will behave as promised. Unfortunately, this might not be the case. We introduce backdoor attacks against text-guided generative models and demonstrate that their text encoders pose a major tampering risk. Our attacks only slightly alter an encoder so that no suspicious model behavior is apparent for image generations with clean prompts. By then inserting a single character trigger into the prompt, e.g., a non-Latin character or emoji, the adversary can trigger the model to either generate images with pre-defined attributes or images following a hidden, potentially malicious description. We empirically demonstrate the high effectiveness of our attacks on Stable Diffusion and highlight that the injection process of a single backdoor takes less than two minutes. Besides phrasing our approach solely as an attack, it can also force an encoder to forget phrases related to certain concepts, such as nudity or violence, and help to make image generation safer.
@inproceedings{struppek23rickrolling, author = {Struppek, Lukas and Hintersdorf, Dominik and Kersting, Kristian}, title = {Rickrolling the Artist: Injecting Backdoors into Text Encoders for Text-to-Image Synthesis}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2023}, pages = {4561--4573}, } -
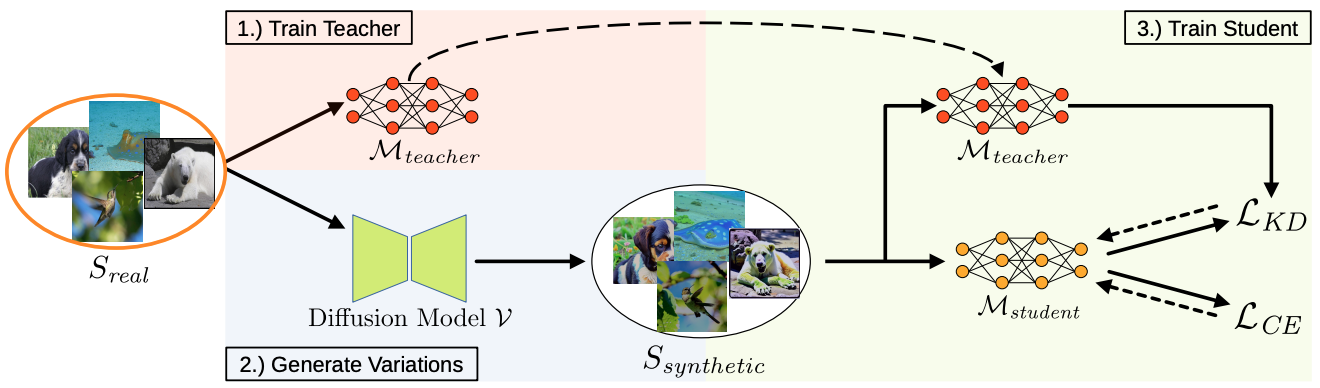 Leveraging Diffusion-Based Image Variations for Robust Training on Poisoned DataLukas Struppek*, Martin B. Hentschel*, Clifton Poth*, Dominik Hintersdorf, and Kristian KerstingNeural Information Processing Systems (NeurIPS) - Workshop on Backdoors in Deep Learning: The Good, the Bad, and the Ugly, 2023
Leveraging Diffusion-Based Image Variations for Robust Training on Poisoned DataLukas Struppek*, Martin B. Hentschel*, Clifton Poth*, Dominik Hintersdorf, and Kristian KerstingNeural Information Processing Systems (NeurIPS) - Workshop on Backdoors in Deep Learning: The Good, the Bad, and the Ugly, 2023Backdoor attacks pose a serious security threat for training neural networks as they surreptitiously introduce hidden functionalities into a model. Such backdoors remain silent during inference on clean inputs, evading detection due to inconspicuous behavior. However, once a specific trigger pattern appears in the input data, the backdoor activates, causing the model to execute its concealed function. Detecting such poisoned samples within vast datasets is virtually impossible through manual inspection. To address this challenge, we propose a novel approach that enables model training on potentially poisoned datasets by utilizing the power of recent diffusion models. Specifically, we create synthetic variations of all training samples, leveraging the inherent resilience of diffusion models to potential trigger patterns in the data. By combining this generative approach with knowledge distillation, we produce student models that maintain their general performance on the task while exhibiting robust resistance to backdoor triggers.
@article{struppek23leveraging, author = {Struppek, Lukas and Hentschel, Martin B. and Poth, Clifton and Hintersdorf, Dominik and Kersting, Kristian}, title = {Leveraging Diffusion-Based Image Variations for Robust Training on Poisoned Data}, journal = {Neural Information Processing Systems (NeurIPS) - Workshop on Backdoors in Deep Learning: The Good, the Bad, and the Ugly}, year = {2023}, } -
 SEGA: Instructing Text-to-Image Models using Semantic GuidanceManuel Brack, Felix Friedrich, Dominik Hintersdorf, Lukas Struppek, Patrick Schramowski, and Kristian KerstingIn Conference on Neural Information Processing Systems (NeurIPS), 2023
SEGA: Instructing Text-to-Image Models using Semantic GuidanceManuel Brack, Felix Friedrich, Dominik Hintersdorf, Lukas Struppek, Patrick Schramowski, and Kristian KerstingIn Conference on Neural Information Processing Systems (NeurIPS), 2023Text-to-image diffusion models have recently received a lot of interest for their astonishing ability to produce high-fidelity images from text only. However, achieving one-shot generation that aligns with the user’s intent is nearly impossible, yet small changes to the input prompt often result in very different images. This leaves the user with little semantic control. To put the user in control, we show how to interact with the diffusion process to flexibly steer it along semantic directions. This semantic guidance (SEGA) generalizes to any generative architecture using classifier-free guidance. More importantly, it allows for subtle and extensive edits, composition and style changes, and optimizing the overall artistic conception. We demonstrate SEGA’s effectiveness on both latent and pixel-based diffusion models such as Stable Diffusion, Paella, and DeepFloyd-IF using a variety of tasks, thus providing strong evidence for its versatility and flexibility.
@inproceedings{brack23sega, author = {Brack, Manuel and Friedrich, Felix and Hintersdorf, Dominik and Struppek, Lukas and Schramowski, Patrick and Kersting, Kristian}, title = {SEGA: Instructing Text-to-Image Models using Semantic Guidance}, booktitle = {Conference on Neural Information Processing Systems (NeurIPS)}, pages = {}, year = {2023}, } -
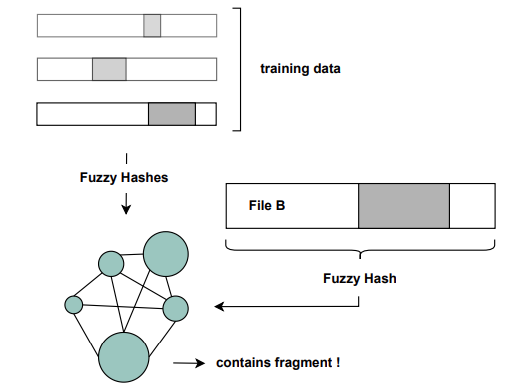 Combining AI and AM – Improving Approximate Matching through Transformer NetworksFrieder Uhlig*, Lukas Struppek*, Dominik Hintersdorf*, Thomas Göbel, Harald Baier, and Kristian KerstingIn Annual DFRWS USA Conference, 2023
Combining AI and AM – Improving Approximate Matching through Transformer NetworksFrieder Uhlig*, Lukas Struppek*, Dominik Hintersdorf*, Thomas Göbel, Harald Baier, and Kristian KerstingIn Annual DFRWS USA Conference, 2023Approximate matching is a well-known concept in digital forensics to determine the similarity between digital artifacts. An important use case of approximate matching is the reliable and efficient detection of case-relevant data structures on a blacklist (e.g., malware or corporate secrets), if only fragments of the original are available. For instance, if only a cluster of indexed malware is still present during the digital forensic investigation, the approximate matching algorithm shall be able to assign the fragment to the blacklisted malware. However, traditional approximate matching functions like TLSH and ssdeep fail to detect files based on their fragments if the presented piece is relatively small compared to the overall file size (e.g., like one-third of the total file). A second well-known issue with traditional approximate matching algorithms is the lack of scaling due to the ever-increasing lookup databases. In this paper, we propose an improved matching algorithm based on transformer-based models from the field of natural language processing. We call our approach Deep Learning Approximate Matching (DLAM). As a concept from artificial intelligence, DLAM gets knowledge of characteristic blacklisted patterns during its training phase. Then DLAM is able to detect the patterns in a typically much larger file, that is DLAM focuses on the use case of fragment detection. Our evaluation is inspired by two widespread blacklist use cases: the detection of malware (e.g., in JavaScript) and corporate secrets (e.g., pdf or office documents). We reveal that DLAM has three key advantages compared to the prominent conventional approaches TLSH and ssdeep. First, it makes the tedious extraction of known to be bad parts obsolete, which is necessary until now before any search for them with approximate matching algorithms. This allows efficient classification of files on a much larger scale, which is important due to exponentially increasing data to be investigated. Second, depending on the use case, DLAM achieves a similar (in case of mrsh-cf and mrsh-v2) or even significantly higher accuracy (in case of ssdeep and TLSH) in recovering fragments of blacklisted files. For instance, in the case of JavaScript files, our assessment shows that DLAM provides an accuracy of 93% on our test corpus, while TLSH and ssdeep show a classification accuracy of only 50%. Third, we show that DLAM enables the detection of file correlations in the output of TLSH and ssdeep even for fragment sizes, where the respective matching function of TLSH and ssdeep fails.
@inproceedings{uhlig23dlam, author = {Uhlig, Frieder and Struppek, Lukas and Hintersdorf, Dominik and Göbel, Thomas and Baier, Harald and Kersting, Kristian}, title = {Combining AI and AM – Improving Approximate Matching through Transformer Networks}, booktitle = {Annual DFRWS USA Conference}, year = {2023}, } -
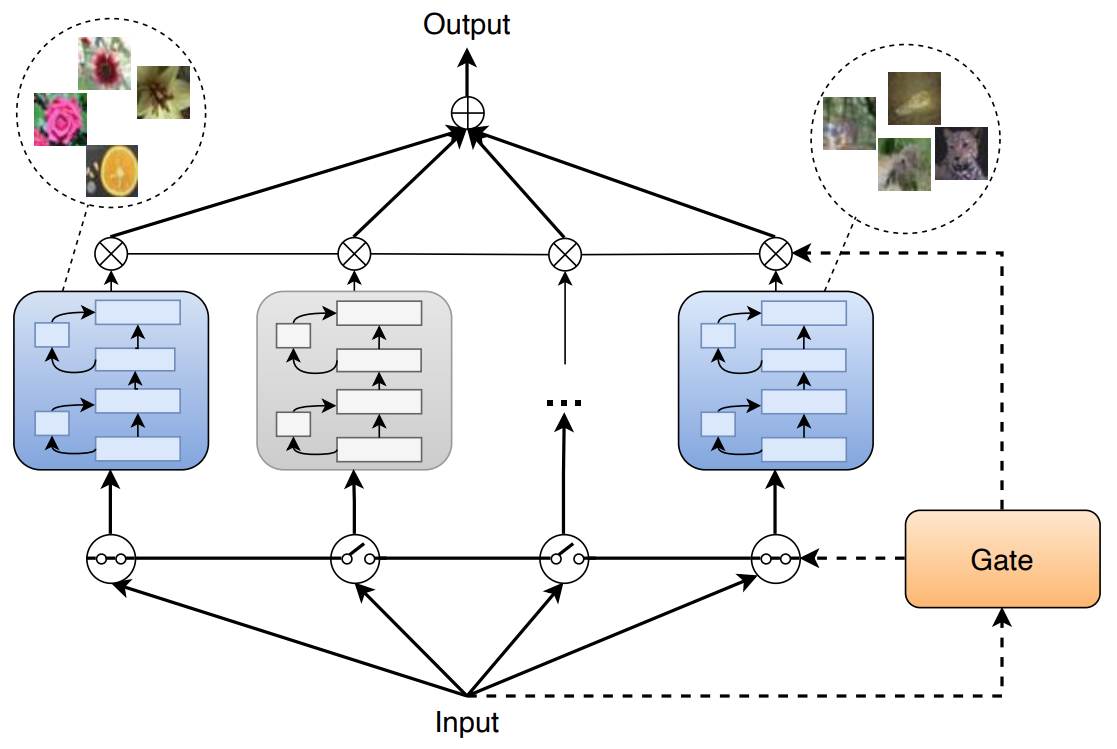 Sparsely-Gated MoE Layers for CNN InterpretabilitySvetlana Pavlitskaya, Christian Hubschneider, Lukas Struppek, and J. Marius ZöllnerIn International Joint Conference on Neural Networks (IJCNN), 2023
Sparsely-Gated MoE Layers for CNN InterpretabilitySvetlana Pavlitskaya, Christian Hubschneider, Lukas Struppek, and J. Marius ZöllnerIn International Joint Conference on Neural Networks (IJCNN), 2023Sparsely-gated Mixture of Expert (MoE) layers have been recently successfully applied for scaling large transformers, especially for language modeling tasks. An intriguing side effect of sparse MoE layers is that they convey inherent interpretability to a model via natural expert specialization. In this work, we apply sparse MoE layers to CNNs for computer vision tasks and analyze the resulting effect on model interpretability. To stabilize MoE training, we present both soft and hard constraint-based approaches. With hard constraints, the weights of certain experts are allowed to become zero, while soft constraints balance the contribution of experts with an additional auxiliary loss. As a result, soft constraints handle expert utilization better and support the expert specialization process, while hard constraints maintain more generalized experts and increase overall model performance. Our findings demonstrate that experts can implicitly focus on individual sub-domains of the input space. For example, experts trained for CIFAR-100 image classification specialize in recognizing different domains such as flowers or animals without previous data clustering. Experiments with RetinaNet and the COCO dataset further indicate that object detection experts can also specialize in detecting objects of distinct sizes.
@inproceedings{pavlitskaya2023moe, author = {Pavlitskaya, Svetlana and Hubschneider, Christian and Struppek, Lukas and Z{\"{o}}llner, J. Marius}, title = {Sparsely-Gated MoE Layers for CNN Interpretability}, booktitle = {International Joint Conference on Neural Networks ({IJCNN})}, year = {2023}, }
2022
-
 Plug & Play Attacks: Towards Robust and Flexible Model Inversion AttacksLukas Struppek, Dominik Hintersdorf, Antonio De Almeida Correia, Antonia Adler, and Kristian KerstingIn International Conference on Machine Learning (ICML), 2022
Plug & Play Attacks: Towards Robust and Flexible Model Inversion AttacksLukas Struppek, Dominik Hintersdorf, Antonio De Almeida Correia, Antonia Adler, and Kristian KerstingIn International Conference on Machine Learning (ICML), 2022Model inversion attacks (MIAs) aim to create synthetic images that reflect the class-wise characteristics from a target classifier’s private training data by exploiting the model’s learned knowledge. Previous research has developed generative MIAs that use generative adversarial networks (GANs) as image priors tailored to a specific target model. This makes the attacks time- and resource-consuming, inflexible, and susceptible to distributional shifts between datasets. To overcome these drawbacks, we present Plug & Play Attacks, which relax the dependency between the target model and image prior, and enable the use of a single GAN to attack a wide range of targets, requiring only minor adjustments to the attack. Moreover, we show that powerful MIAs are possible even with publicly available pre-trained GANs and under strong distributional shifts, for which previous approaches fail to produce meaningful results. Our extensive evaluation confirms the improved robustness and flexibility of Plug & Play Attacks and their ability to create high-quality images revealing sensitive class characteristics.
@inproceedings{struppek2022ppa, booktitle = {International Conference on Machine Learning (ICML)}, pages = {20522--20545}, year = {2022}, author = {Struppek, Lukas and Hintersdorf, Dominik and Correia, Antonio De Almeida and Adler, Antonia and Kersting, Kristian}, title = {Plug & Play Attacks: Towards Robust and Flexible Model Inversion Attacks}, } -
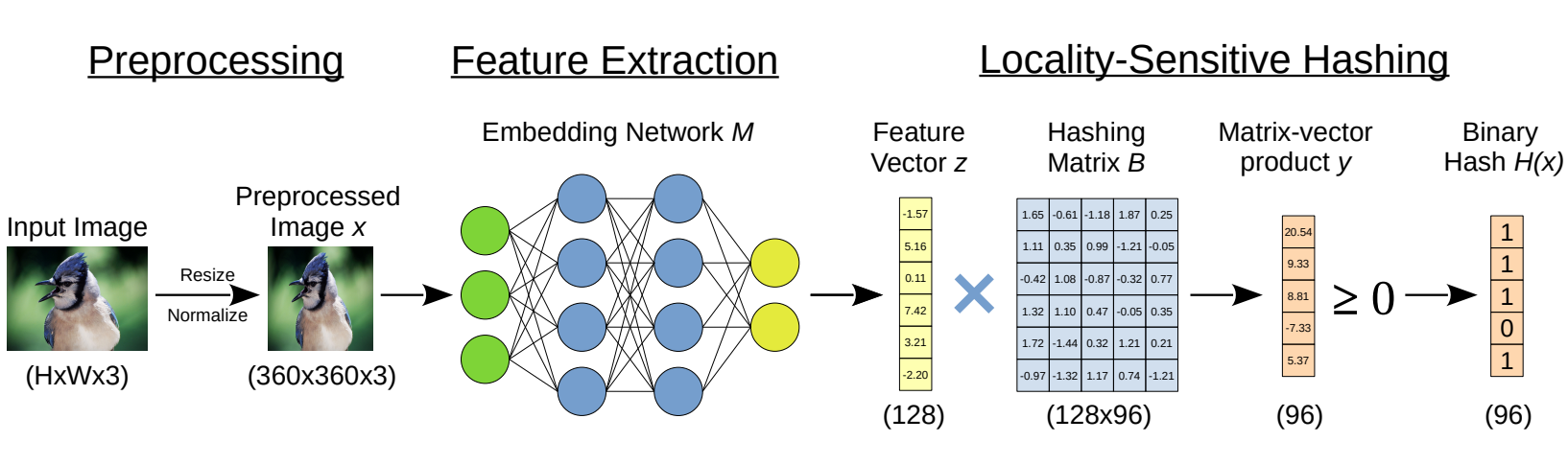 Learning to Break Deep Perceptual Hashing: The Use Case NeuralHashLukas Struppek*, Dominik Hintersdorf*, Daniel Neider, and Kristian KerstingIn ACM Conference on Fairness, Accountability, and Transparency (FAccT), 2022
Learning to Break Deep Perceptual Hashing: The Use Case NeuralHashLukas Struppek*, Dominik Hintersdorf*, Daniel Neider, and Kristian KerstingIn ACM Conference on Fairness, Accountability, and Transparency (FAccT), 2022Apple recently revealed its deep perceptual hashing system NeuralHash to detect child sexual abuse material (CSAM) on user devices before files are uploaded to its iCloud service. Public criticism quickly arose regarding the protection of user privacy and the system’s reliability. In this paper, we present the first comprehensive empirical analysis of deep perceptual hashing based on NeuralHash. Specifically, we show that current deep perceptual hashing may not be robust. An adversary can manipulate the hash values by applying slight changes in images, either induced by gradient-based approaches or simply by performing standard image transformations, forcing or preventing hash collisions. Such attacks permit malicious actors easily to exploit the detection system: from hiding abusive material to framing innocent users, everything is possible. Moreover, using the hash values, inferences can still be made about the data stored on user devices. In our view, based on our results, deep perceptual hashing in its current form is generally not ready for robust client-side scanning and should not be used from a privacy perspective.
@inproceedings{struppek2022learning, year = {2022}, author = {Struppek, Lukas and Hintersdorf, Dominik and Neider, Daniel and Kersting, Kristian}, title = { Learning to Break Deep Perceptual Hashing: The Use Case NeuralHash }, booktitle = {ACM Conference on Fairness, Accountability, and Transparency (FAccT)}, pages = {58--69}, } -
 To Trust or Not To Trust Prediction Scores for Membership Inference AttacksDominik Hintersdorf*, Lukas Struppek*, and Kristian KerstingIn International Joint Conference on Artificial Intelligence (IJCAI) , 2022
To Trust or Not To Trust Prediction Scores for Membership Inference AttacksDominik Hintersdorf*, Lukas Struppek*, and Kristian KerstingIn International Joint Conference on Artificial Intelligence (IJCAI) , 2022Membership inference attacks (MIAs) aim to determine whether a specific sample was used to train a predictive model. Knowing this may indeed lead to a privacy breach. Most MIAs, however, make use of the model’s prediction scores - the probability of each output given some input - following the intuition that the trained model tends to behave differently on its training data. We argue that this is a fallacy for many modern deep network architectures. Consequently, MIAs will miserably fail since overconfidence leads to high false-positive rates not only on known domains but also on out-of-distribution data and implicitly acts as a defense against MIAs. Specifically, using generative adversarial networks, we are able to produce a potentially infinite number of samples falsely classified as part of the training data. In other words, the threat of MIAs is overestimated, and less information is leaked than previously assumed. Moreover, there is actually a trade-off between the overconfidence of models and their susceptibility to MIAs: the more classifiers know when they do not know, making low confidence predictions, the more they reveal the training data.
@inproceedings{hintersdorf2022trust, pages = {3043--3049}, booktitle = {International Joint Conference on Artificial Intelligence ({IJCAI}) }, year = {2022}, author = {Hintersdorf, Dominik and Struppek, Lukas and Kersting, Kristian}, title = { To Trust or Not To Trust Prediction Scores for Membership Inference Attacks }, } -
 Investigating the Risks of Client-Side Scanning for the Use Case NeuralHashDominik Hintersdorf*, Lukas Struppek*, Daniel Neider, and Kristian KerstingIn Working Notes of the 6th Workshop on Technology and Consumer Protection (ConPro) @ 43th IEEE Symposium on Security and Privacy, 2022
Investigating the Risks of Client-Side Scanning for the Use Case NeuralHashDominik Hintersdorf*, Lukas Struppek*, Daniel Neider, and Kristian KerstingIn Working Notes of the 6th Workshop on Technology and Consumer Protection (ConPro) @ 43th IEEE Symposium on Security and Privacy, 2022Regulators around the world try to stop the distribution of digital criminal content without circumventing the encryption methods in place for confidential communication. One approach is client-side scanning (CSS) which checks the content on the user’s device for illegality before it is encrypted and transmitted. Apple has recently revealed a client-side deep perceptual hashing system called NeuralHash to detect child sexual abuse material (CSAM) on user devices before the images are encrypted and uploaded to its iCloud service. After its public presentation, criticism arose regarding the users’ privacy and the system’s reliability. In this work, we present an empirical analysis of client-side deep perceptual hashing based on NeuralHash. We show that such systems are not robust, and an adversary can easily manipulate the hash values to force or prevent hash collisions. Such attacks permit malicious actors to exploit the detection system: from hiding abusive material to framing innocent users, a large variety of attacks is possible.
@inproceedings{hintersdorf2022conpro_learning, year = {2022}, author = {Hintersdorf, Dominik and Struppek, Lukas and Neider, Daniel and Kersting, Kristian}, title = {Investigating the Risks of Client-Side Scanning for the Use Case NeuralHash}, booktitle = {Working Notes of the 6th Workshop on Technology and Consumer Protection (ConPro) {@} 43th IEEE Symposium on Security and Privacy}, }